本文分析 redis 集群如何实现
打开集群模式
配置
- 配置文件
cluster-enabled yes 打开集群模式
cluster-config-file nodes.conf 指定集群配置文件为 nodes.conf,这个文件由 redis 负责读写
cluster-node-timeout 5000 设定集群超时时间
集群模式下只能使用 db0。
创建集群
节点首次以 cluster-enabled yes 模式运行时,它们是互相独立的节点,节点通过 MEET 命令认识其他节点,从而形成一个集群
假设有 3 个独立节点
| 代号 | IP : 端口 |
|---|---|
| A | 127.0.0.1:7000 |
| B | 127.0.0.1:7001 |
| C | 127.0.0.1:7002 |
命令
1 | redis-cli -c -p 7000 cluster meet 127.0.0.1 7001 |
将 A 介绍给 B,这时 A 就开始和 B 握手(发送 MEET 消息),握手成功后 A 和 B 就组成一个 2 节点的集群。用 cluster nodes 命令可以看到集群的信。这时 A 和 B 各自的 cluster-config-file 也会记录集群的信息。
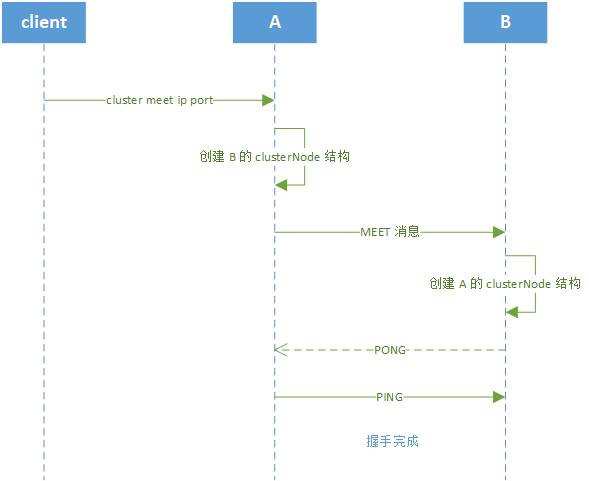
之后用命令
1 | redis-cli -c -p 7000 cluster meet 127.0.0.1 7002 |
将 C 介绍给 A, A 在和 C 握手并保存好 C 的信息后,会通过 Gossip 协议给 C 的信息发送给 B,将 B 的信息发送给 C。B 和 C 互相握手后就组成一个 3 节点的集群
分配 slot
redis 集群通过分片的方式保存键值对:整个个集群被会成 16384(2^14) 个 slot,所有的键都分配到这 16384 个 slot 中,然后集群中的节点专门负责处理其中指定的 slot。
在集群创建后,由于没有分配好 slot,整个集群还是处于下线状态,需要将这 16384 个 slot 全部指定后,集群才处于上线状态
1 | # redis-cli -c -p 7000 cluster info | head -n 1 |
使用 cluster addslots 命令分配 slot
1 |
|
分配完成后,集群处于上线状态
1 | # redis-cli -c -p 7000 cluster info | head -n 1 |
上线后,就可以通过客户端向集群任意节点发送命令
1 | redis-cli -p 7000 set k4 val |
由于 key k4 在 8455 这个 slot,而 8455 由 B 节点处理,所以 redis 返回
1 | (error) MOVED 8455 127.0.0.1:7001 |
意思是需要将命令转发到 127.0.0.1:7001 执行,如果给 redis-cli 加上 -c 选项,客户端就会自动处理这种转发
1 | # redis 返回 OK |
扩、缩容,迁移 slot
当集群进行扩容或缩容时,需要将 slot 迁移到另外的节点上,这个过程可以在线进行。
以扩容为例,假设新增了一个节点 D,然后需要将 16383 号 slot 迁移到节点 D
首先将节点 D 加入群集
1 | redis-cli -c -p 7000 cluster meet 127.0.0.1 7003 |
然后通过 setslot 命令进行重新分片
1 | # 1. 对目标节点发送, source_id 是源节点的 ID, 可以通过 cluster nodes 得到 |
在数据迁移的过程中,可能会对 16383 号 slot 的数据进行读写
对于数据读取,有两种情况
如果 key 还在源节点,直接在源节点执行
如果 key 不在源节点,返回 ASK 到客户端,让客户端转到目标节点执行
数据写同理
实现
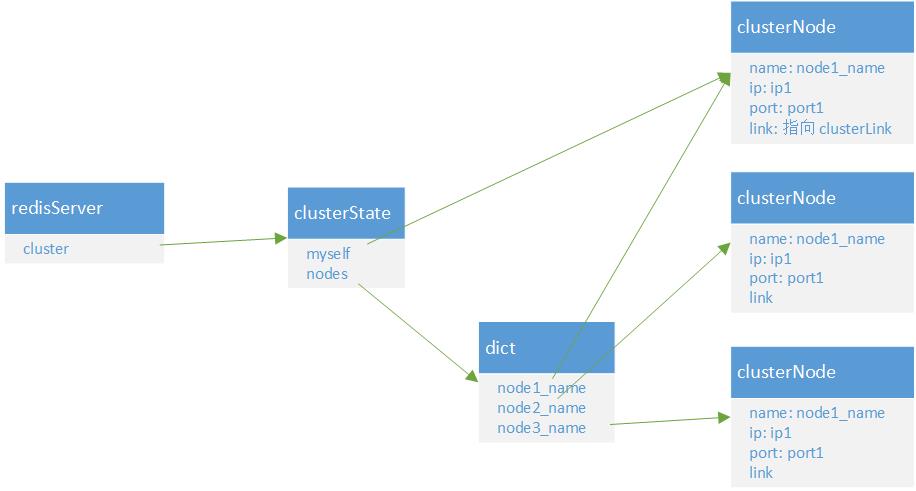
集群数据结构
关键数据结构有
1 |
|
集群间发送消息
集群间消息的数据结构由 clusterMsg 定义
1 |
|
在 ServerCron 函数中判断如果集群模式打开,会调用 clusterCron 函数,使节点可以周期性地发送消息,clusterCron 方法每秒执
行 10 次
服务器启动时,调用 clusterInit 函数, clusterInit 函数侦听 server.port + 10000 端口,clusterAcceptHandler 函数用于处理来自 server.port + 10000 的连接请求。 clusterAcceptHandler 收到连接请求后,注册 clusterReadHandler 为 IO 事件处理器
clusterReadHandler 读出数据包然后调用 clusterProcessPacket 处理消息
发送 MEET 消息
MEET 消息用于握手。集群命令在 cluster.c 的 clusterCommand 函数处理,当一个节点接收到 meet 命令时,它会调用 clusterStartHandshake 方法开始握手,clusterStartHandshake 调用 createClusterNode 创建节点信息 clusterNode,并将新的 clusterNode 加入到 server.cluster->nodes 这个字典中。
当执行 clusterCron 时,对新节点进行建立连接,注册 clusterReadHandler 为 IO 事件处理器,并通过 clusterSendPing 发送 MEET 消息。 MEET 消息带有 floor(节点 / 10) 个其他节点的信息(节点名, IP, 集群端口,flag)响应 MEET 消息
节点收到 MEET 消息后,创建一个新的 clusterNode 结构并加入到自己的 server.cluster->nodes 中,然后处理消息中关于其他节点的信息(节点状态,角色等),最后给发送者发出 PONG 消息。发送 PING、PONG 消息
MEET、PING 和 PONG 消息都是通过 clusterSendPing 函数进行发送,都会带上节点保存的关于其他节点的信息响应 PING 和 PONG 消息
处理消息中关于其他节点的信息,处理 PING 消息的话,还会返回 PONG 消息发送 FAIL 消息
在处理 PING 等消息的过程中,如果某个节点被报告为 CLUSTER_NODE_FAIL 并且这个节点也被当前节点检测到为 FAIL,那么当前节点(如果是 master 的话)会调用 clusterSendFail 函数向所有它知道的节点发送 FAIL 消息, FAIL 消息命令失效节点的节点名处理 FAIL 消息
将失效节点对应的 clusterNode 中的 flags 标记为 CLUSTER_NODE_FAIL发送 PUBLISH 消息
当一个节点收到 publish 命令时,它调用 clusterPropagatePublish 函数向整个集群(所有它知道的节点)发出 PUBLISH 消息处理 PUBLISH 消息
调用 pubsubPublishMessage 函数处理UPDATE 消息是为了更新节点的 slot 配置
命令执行
普通命令
普通的 redis 命令由 processCommand 函数处理,在 processCommand 中,检查如果 server.cluster_enabled 打开,并且命令有 key 参数,就通过 getNodeByQuery 计算出 key 在哪个节点上,然后通过 clusterRedirectClient 返回 MOVE 或 ASKcluster 命令
在 server.c 中注册了由 clusterCommand 处理 cluster 命令,所有的 cluster 子命令在 clusterCommand 处理(cluster 命令没有 key 参数,所以在 processCommand 函数中不会被转发)addslots、delslots 命令
addslots、delslots 命令都是用于分配 slot。调用 clusterAddSlot 或 clusterDelSlot 修改 clusterNode.slots 这个 bitmap 的标志位。从这里也可以看出 slot 只是标记,并没有一个 slot 对应的数据结构用于保存数据,仅仅通过 slot 将数据分到不同的节点而已setslot
修改 slot 的属性。setslot (slot) migrating (targetId)
将 server.cluster->migrating_slots_to[slot] 设置为 targetId,这样在 getNodeByQuery 中就会考虑到这个 slot 是不是在 migrating,该节点上有没有对应的 key,如果没有就转发到 targetIdsetslot (slot) importing (targetId)
同 migrating 类似,修改 server.cluster->importing_slots_from[slot] 为 targetIdsetslot (slot) stable
将 server.cluster->importing_slots_from[slot] 和 server.cluster->importing_slots_from[slot] 设置为 NULLsetslot (slot) node (targetId)
通过 clusterDelSlot 和 clusterAddSlot 将 slot 设置为 targetId 这个节点,同时如果 server.cluster->importing_slots_from[slot] 有值,就设置为 NULL
故障检查以及转移
故障检查
每个 clusterCron 周期, 向其他节点发送 PING 消息检查连通情况- 每个节点都会随机挑选 5 个其他节点,选择其中最久没收到 PONG 消息的节点(即 clusterNode.pong_received 的值最小),向其发送 PING 消息
- 如果没给目标节点发送 PING 且 now - clusterNode->pong_received > redisServer.cluster_node_timeout/2(cluster_node_timeout 默认是 15000),向其发送 PING
在每个 clusterCron 周期检查每个节点,如果向节点发送了 PING 且 now - clusterNode->ping_sent > redisServer.cluster_node_timeout,则认为该节点可能失效,记录为 CLUSTER_NODE_PFAIL
如果在收到其他节点的 PING/PONG/FAIL 消息中,如果有 (server.cluster->size / 2) + 1 个节点记录该 CLUSTER_NODE_PFAIL 节点的状态也是 CLUSTER_NODE_PFAIL 或 CLUSTER_NODE_FAIL(在 clusterProcessGossipSection 函数处理),则认为该节点已经失效,将该节点的状态记录为 CLUSTER_NODE_FAIL(FAIL 消息的话,直接将节点设置为 CLUSTER_NODE_FAIL)
节点将失效节点的信息通过 FAIL 消息广播出去
故障转移
- 自动故障转移
- 每个 clusterCron 周期, slave 节点会调用 clusterHandleSlaveFailover 函数,如果它的 master 失效,它就向其他节点广播 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息请求投票;
- master 节点收到 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息后,节点判断能否投票给请求投票方(在 clusterSendFailoverAuthIfNeeded 处理,只允许 master 失效的 slave 节点发起投票,且当前时间 - 该节点上次投票时间 > server.cluster_node_timeout * 2 才会投),然后给发起节点发送 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息;
- 发起投票的节点收到 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 后,server.cluster->failover_auth_count 加 1,当 server.cluster->failover_auth_count > (server.cluster->size / 2) + 1 (在 clusterHandleSlaveFailover 处理),slave 切换到 master 模式(clusterFailoverReplaceYourMaster 函数),然后广播 PONG 消息给所有节点更新信息。
- 人工故障转移
- 可以用 cluster failover 命令进行人工故障转移。如果 slave 节点可以成为 master(在 clusterHandleManualFailover 函数中检查 server.cluster->mf_master_offset),如果不能,就返回;如果可以,slave 节点向 master 发送 CLUSTERMSG_TYPE_MFSTART 消息,master 收到 CLUSTERMSG_TYPE_MFSTART 后就停止向 clinet 提供服务一段时间(CLUSTER_MF_TIMEOUT * 2, CLUSTER_MF_TIMEOUT = 5000 ms),这样其他节点就会认为 master 失效,开始自动故障转移的过程
- 如果加上 takeover 参数,就直接将节点设置成 master 而不会进行自动故障转移
- 如果加上 force 参数,立即开始 failover,而不检查 offset
- 自动故障转移