分析 rocketmq 的如何实现消息的存储
简介
store 模块定义了 rocketmq 如何将消息存储在文件系统。只要消息被刷盘持久化至磁盘文件中,那么 Producer 发送的消息就不会丢失,而 Consumer 也就肯定有机会去消费这条消息。
消息存储的层次结构
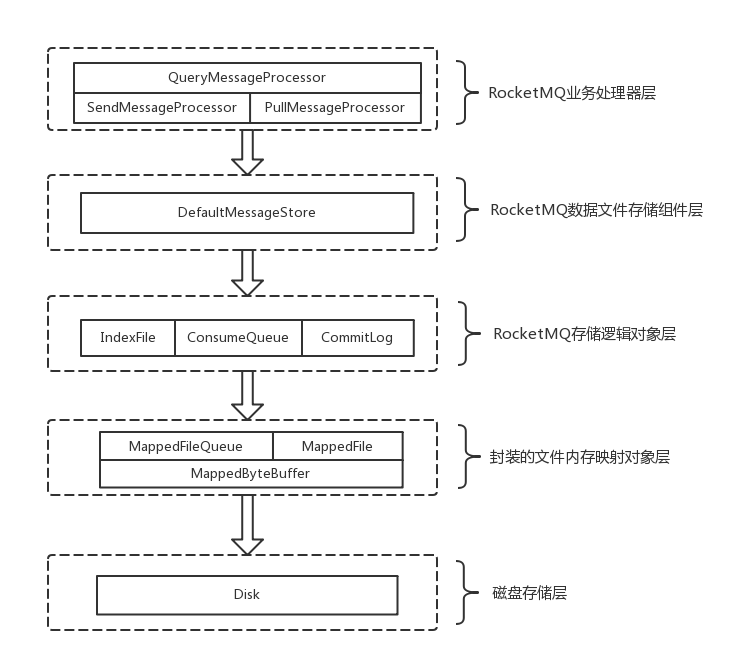
rocketmq 文件存储模型层次结构如上图所示,概念上可以分为 5 层:
- rocketmq 业务处理器层,是 Broker 端对消息进行读取和写入的业务逻辑入口
- rocketmq 数据存储组件层,主要是 rocketmq 的存储核心类 DefaultMessageStore,为 rocketmq 消息数据文件的访问入口
- rocketmq 存储逻辑对象层,主要是三个模型类 IndexFile、ConsumerQueue 和 CommitLog
- 封装的文件内存映射层,采用 NIO 中的 MappedByteBuffer 和 FileChannel 完成数据文件读写
- 磁盘存储层,部署 rocketmq 服务器所用的磁盘
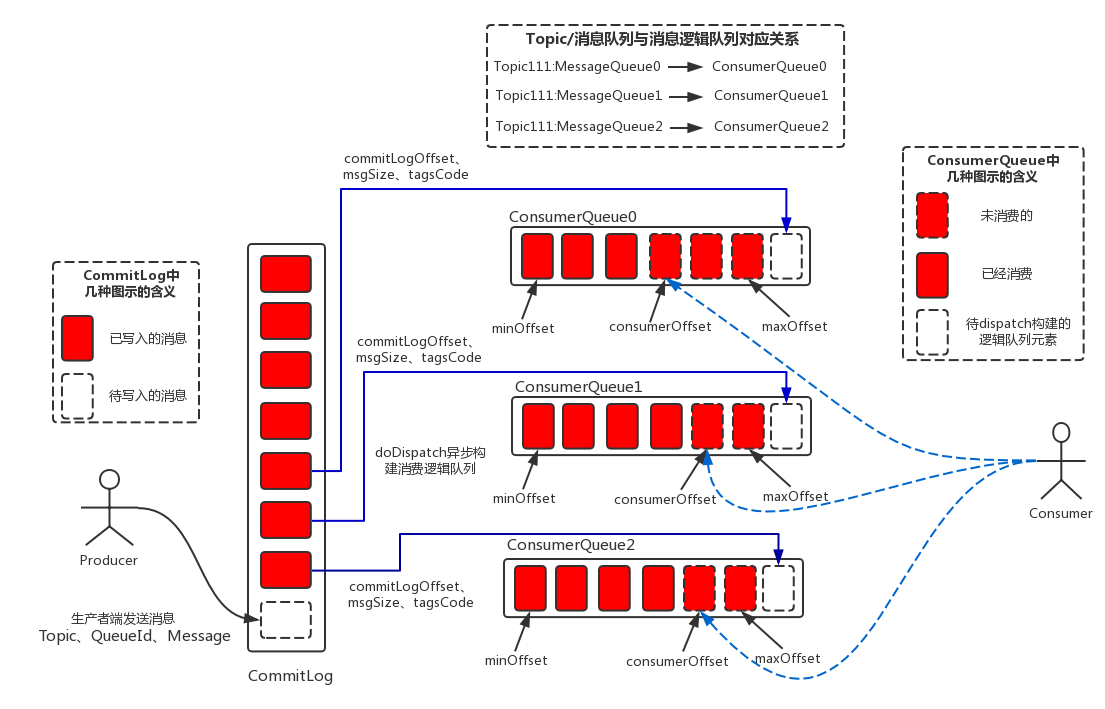
存储逻辑对象层说明:
- 单个 broker 的所有消息都保存在 commit log 文件
- 生产者发送消息到 broker,broker 先写到 commit log
- 将消息在 commit log 在的位置记录到 consume queue(逻辑消费队列)
consume queue 维护了 3 个变量:
minOffset 表示 consume queue 中是早一个消息的逻辑下标
consumerOffset 表示目前消费到的逻辑下标(保存在 consumerOffset),
maxOffset 表示新消息在 consume queue 中的逻辑下标 - 消费者消费消息时,是按顺序从 consume queue 得到消息的存储位置,然后到 commit log 中取消息内容
- consume queue 按 Topic 组合,每个 Topic 下有多个 consume queue
- index 文件提供快速查找消息的方法,而且通过 index 文件来找消息不影响消息的消费
对于 consume queue, 采用顺序读写,速度较快,而 commit log 写入时是顺序写入,读取进是随机读取,读的效率偏低。
消费一条消息需要先读 consume queue 再读 commit log,有一定的开销
CommitLog 格式
用于保存消息,默认保存在 store/commitlog 目录下,每个文件都是 1GB,按顺序保存消息。
文件名每个都是 20 位,左边补0。第一个文件文件名是 00000000000000000000,起始位置的逻辑位置是 0,即偏移量是0。当第一个文件写满后,第二个文件文件名是 00000000001073741824(1G),起始位置的逻辑位置是 1073741824,即当要查找 commitLog 第 1073741825 的位置时,就读第二个文件的第 1 个字节,由此类推。
CommitLog 的内部类 MessageExtBatchEncoder 定义怎么将消息体变成字节流,DefaultAppendMessageCallback 的 doAppend 定义怎么将流读到消息体。一个消息包括以下内容:
| 序号 | 字段简称 | 字段大小(字节),类型 | 字段含义 |
|---|---|---|---|
| 1 | TOTALSIZE | 4,Integer | 消息总长度 |
| MAGICCODE | 4,Integer | 魔术数,CommitLog. MESSAGE_MAGIC_CODE | |
| BODYCRC | 4,Integer | 消息体CRC | |
| QUEUEID | 4,Integer | ||
| 5 | FLAG | 4,Integer | |
| QUEUEOFFSET | 8,Long | ||
| PHYSICALOFFSET | 8,Long | 消息在commitLog中的物理起始地址偏移量 | |
| SYSFLAG | 4,Integer | ||
| BORNTIMESTAMP | 8,Long | 消息产生时间戳 | |
| 10 | BORNHOST | 8,byte buffer | 消息生产者地址, IP:Port |
| STORETIMESTAMP | 8,Long | 消息在 broker 的时间戳 | |
| STOREHOSTADDRESS | 8,byte | buffer 消息存储到broker的地址,IP:Port | |
| RECONSUMETIMES | 4,Integer | ||
| Prepared Transaction Offset | 8,Long | ||
| 15 | BODY LENGTH | 4,Integer | BODY 的长度 |
| BODY | BODY LENGTH | ||
| TOPIC LENGTH | 1,byte | TOPIC 的长度 | |
| TOPIC | TOPIC LENGTH | ||
| PROPERTIES LENGTH | 2,Short | PROPERTIES 的长度 | |
| 20 | PROPERTIES | PROPERTIES LENGTH | 消息的属性 |
ConsumeQueue
默认保存在 store/consumequeue/${Topic}/${queueid} 目录下,每个文件都是 600 万字节(5.7MB)
文件名每个都是 20 位,左边补 0,第一个文件文件名是 00000000000000000000, 与 CommitLog 的规则类似
每个 entry 包含如下内容:
| 序号 | 字段简称 | 字段大小(字节),类型 | 字段含义 |
|---|---|---|---|
| 1 | offset | 8,Long | |
| size | 4,Integer | ||
| tagsCode | 8,Long |
Index
记录某个 key 在 commit log 中的位置。索引文件由头,hashSlot,和 index 组成。
文件头包括有如下字段
| 序号 | 字段简称 | 字段大小(字节),类型 | 字段含义 |
|---|---|---|---|
| 1 | beginTimestamp | 8,Long | |
| endTimestamp | 8,Long | ||
| beginPhyOffset | 8,Long | ||
| endPhyOffset | 8,Long | ||
| 5 hashSlotCount | 4,Integer | ||
| indexCount | 4,Integer | 索引的数量 |
一个 hashSlot 占 4 字节,一共有 hashSlotNum 个(在 MessageStoreConfig.maxHashSlotNum 配置项定义)。一个 hashSlot 的值表示这个 hash 值的 index 的下标
index 有如下字段
| 序号 | 字段简称 | 字段大小(字节),类型 | 字段含义 |
|---|---|---|---|
| 1 | keyHash | 4,Integer | 散列值 |
| phyOffset | 8,Long | 消息 在 commit log 中的位置 | |
| timeDiff | 4,Integer | storeTimestamp 到 beginTimestamp 的差 | |
| slotValue | 4,Integer | hashSlot 的旧值,表示同样 hash 值的 index 的下标,相当于链表的 pre 指针。用拉链法解决 hash 冲突 |
消息存储的底层技术
内存映射文件
将文件内容映射到内存中,这里的映射是硬盘上文件的位置与进程逻辑地址空间的一一对应,然后文件的读写通过访问这段内存实现,这样就减少了 read / write 等系统调用。
使用 read / write 等系统调用,读操作的话操作系统先将文件的内存加载到内核空间,再复制到用户进程空间;写操作的话会先将用户进程空间复制到内核空间再写入磁盘。内存映射文件技术减少了这些中间操作,从而提升效率。
java 中通过 FileChannel 的 map 成员方法可以打开内存映射文件
PageCache 以及文件预热
系统的所有文件 I/O 请求,操作系统都是通过 page cache 机制实现的。对于操作系统来说,磁盘文件都是由一系列的数据块顺序组成,数据块的大小由操作系统本身而决定,x86 的 linux 中一个标准页面大小是 4KB。
操作系统内核在处理文件 I/O 请求时,首先到 page cache 中查找(page cache 中的每一个数据块都设置了文件以及偏移量地址信息),如果未命中,则启动磁盘 I/O,将磁盘文件中的数据块加载到 page cache 中的一个空闲块,然后再 copy 到用户缓冲区中。
page cache 本身也会对数据文件进行预读取,对于每个文件的第一个读请求操作,系统在读入所请求页面的同时会读入紧随其后的少数几个页面。因此,想要提高 page cache 的命中率(尽量让访问的页在物理内存中),从硬件的角度来说肯定是物理内存越大越好。从操作系统层面来说,访问 page cache 时,即使只访问 1k 的消息,系统也会提前预读取更多的数据,在下次读取消息时, 就很可能可以命中内存。
每当创建一个新的 commit log 内存映射文件,rocketmq 会每隔 4k 写入一个 0,使得整个文件都会加载到内存,然后用 mlock 锁定内存。这样 commit log 的读写都会通过内存进行,可以有效提高消息的 I/O 效率。
LibC 系统调用
利用 JNA 加载 C Runtime 库,并调用其中的 API
1 | public interface LibC extends Library { |
消息存储的功能实现
MappedFile & MappedFileQueue
MappedFile 操作内存映射文件,负责用内存映射的方式读写文件。 MappedFile 继承了 ReferenceResource,ReferenceResource 采用引用计数的方式管理资源。
MappedFile 有两种工作方式,由 MessageStoreConfig.isTransientStorePoolEnable 配置项控制
当 MessageStoreConfig.isTransientStorePoolEnable 为 true 时,MappedFile 在 init 会传入 TransientStorePool 对象,并从中取出 ByteBuffer 给 writeBuffer 成员赋值;当 MessageStoreConfig.isTransientStorePoolEnable 为 false 时则不传入
当 writeBuffer 非空时,就使用 writeBuffer 进行读写,否则使用 mappedByteBuffer 进行读写
主要区别是 flush 和 commit 方法不同:
- 使用 writeBuffer,读写操作其实是先写到另外的 byteBuffer,而不是文件映射到的 mappedByteBuffer
commit 将 writeBuffer 写入 fileChannel
flush 方法调用 fileChannel 的 force,强制将 fileChannel 所有更新写入存储设备,因为这时不使用 mappedByteBuffer 读写,所以不用管 mappedByteBuffer - 使用 mappedByteBuffer
commit 方法什么都不做
flush 方法调用 mappedByteBuffer 的 force,强制 mappedByteBuffer 的所有更新写入到存储设备
因为 MappedFile 总是多个出现,例如 commit log 就由多个文件组成,所以用列表组织起来,并提供服务。所有对 MappedFile 的操作其实都要经过 MappedFileQueue。
MappedFileQueue 的主要成员有
1 |
|
commit log
CommitLog 类实现了对 commit log 文件的读写。 CommitLog 文件保存在 ${storePath}/commitlog/ 目录下。
1 |
|
同步刷盘 VS 异步刷盘
handleDiskFlush 处理磁盘的刷新。当使用同步方式时,commit log 写到磁盘后,putMessage 才返回;当使用异步方式时,commit log 写到内存就返回,由专门的线程将内存刷新到磁盘。
1 |
|
HA(同步双写 VS 异步复制)
handleHA 实现 master 到 slave 的同步双写,如果是采用异步复制的方法,这个方法会直接返回
1 |
|
HA
HAService 类实现了 commit log 的 master-slave 同步。broker 启动时,会打开 listen + 2 的端口侦听来自其实 broker 的 HA 连接。master 可以同步到 slave, slave 也可以同步到其他 slave。
HA 服务使用原生 NIO 实现通信, 主要有几个部分组成
- HAService:包装各个同步组件,主要有嵌套类来实现功能
- AcceptSocketService: 侦听来自其他 broker 的连接请求,accept 后创建连接对象 HAConnection
- GroupTransferService:检查数据是否已经写到 slave
- HAClient:连接 master,连接建立后接收 master 发送的数据并写到 commit log,然后向 master 报告自己的 maxOffset,以便控制发送速度
- HAConnection:显然由同步的源端使用,主要功能由嵌套类 ReadSocketService 和 WriteSocketService 实现
- ReadSocketService: 接收来自 slave 报告的 maxOffset,并通知 GroupTransferService
- WriteSocketService:从 commit log 中读数据并发送给 slave
master 相关代码
1 |
|
slave 相关代码
1 | public class HAService { |
consume queue
ConsumeQueue 记录消息在 CommitLog 中的位置,一个 ConsumeQueue 对象表示一个 Topic 下的一个队列。
ConsumeQueue 按 topic 和 队列 ID 保存在 ${storePath}/consumequeue/${topic}/${queueId} 目录下。
1 |
|
index
索引文件由 IndexFile 类封装读写,IndexService 负责提供服务
1 | public class IndexService { |
check point 与文件完整性检查
文件 checkpoint
checkpoint 文件保存在 ${storePath}/checkpoint 中,由 StoreCheckpoint 类负责读写。
checkpoint 文件只保存 3 个值,分别是 physicMsgTimestamp,logicsMsgTimestamp,indexMsgTimestamp
physicMsgTimestamp 表示 commit log 中最后一条有效消息的存储时间(落盘时间)
logicsMsgTimestamp 表示 consume queue 中最后一条有效消息的存储时间(逻辑位置)
indexMsgTimestamp 表示索引文件中,最新的消息的索引时间。每个索引文件都有一个 daemon 线程 负责 flush, flush 的时候会设置 check point。
从文件恢复到对象
DefaultMessageStore 启动后,会生成 ${storePath}/abort 文件,当 DefaultMessageStore 正常退出时, 会删除 abort。所以,如果 abort 文件存在,则说明前一次是异常退出,如果文件不存在,则说明前一次是正常退出。
CommitLog 对象的恢复过程,主要是恢复 mappedFileQueue 对象的 flushedWhere, committedWhere 成员。
首先搜索 ${storePath}/commitlog 目录,将每个文件生成 MappedFIle 对象保存到 MappedFileQueue
- 如果是正常退出,那么从倒数第 3 个 commit log 文件开始恢复。检查每条消息,找到最后的写入位置然后更新 mappedFileQueue 对象的成员
- 如果是非正常退出,由尾部开始往前检查 commit log 文件,如果文件第一条消息存储时间比 checkpoint 保存的小,就从这个文件开始做恢复。循环检查每条消息,更新 mappedFileQueue 对象的成员
ConsumeQueue 的恢复类似