转载自 https://mp.weixin.qq.com/s/EaTABiufJ-bs4_8bU3nH8w
故障模拟
本文是来讲解一下如何模拟将 CPU、IO 打满的。将 CPU 打满,原理很简单,跑一个 CPU 密集型的程序即可;将 IO 打满,原理也很简单,狂写不止即可。下面我们先来看一个打满 CPU 的脚本:
1 | cat << EOF > /tmp/infiniteburn.sh |
这个脚本是什么意思呢?这里简单讲解一下。首先是先建一个 /tmp/infiniteburn.sh 脚本,这个脚本中的内容即为:
1 |
|
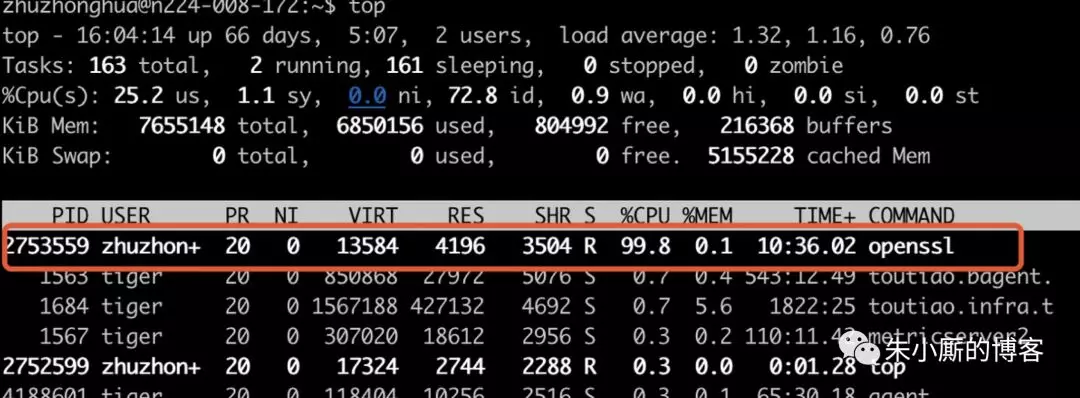
这个脚本就是用来打满 CPU 的。这里的 openssl speed 是用来测试加密算法性能的,这是一种CPU密集型的计算。运行一个脚本只会打满一个 CPU,所以这里还有下面的
1 | for i in {1..32} |
这个操作,用来执行 32 次 /tmp/infiniteburn.sh 脚本。这里假设的前提是当前机器的内核个数不会超过 32,如果超过了,那么修改一下 32 这个数值即可。
再来看下如何打满 IO,对应的模拟脚本如下:
1 |
|
这个脚本和上面的第一个脚本相同,首先是先建一个 /tmp/loopburnio.sh 的过度脚本,这个脚本中的内容是:
1 | while true; |
这里用到了 linux 的 dd 命令,它用于读取、转换并输出数据。dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
1 | dd if=/dev/urandom of=/burn bs=1M count=1024 iflag=fullblock |
这条命令的意思是采用 dd 工具模拟读写。if 指定输入的文件名,of 指定输出的文件名,bs 同时设置读写块的大小为 1M,count 是指仅拷贝 1024 个块,块大小等于 bs 指定的字节数。iflag=fullblock 表示堆积满 block。
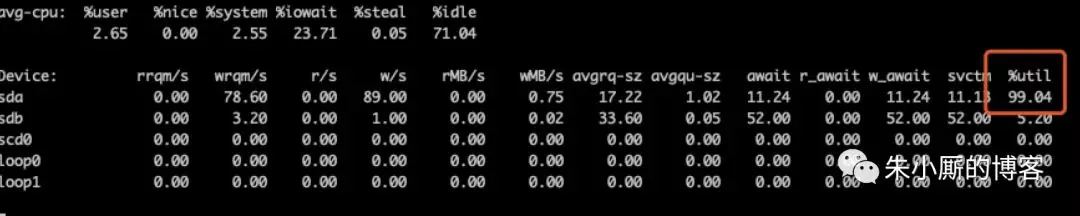
运行这个脚本,然后使用 iostat 命令查看 IO 的使用情况:
原理我都懂,要它有啥用
上面的两个脚本是 Simian Army中 的故障注入的实现,Simian Army 或许小伙伴们没有听过,那么 Chaos Monkey 肯定得听过了吧。Chaos Monkey 是Netflix 的产品,如果你还不知道 Netflix 是什么,那么赶紧看一下《明星公司之Netflix》这篇来恶补一下吧。Chaos Monkey 通过关停一个或多个虚拟机来模拟 service 实例的失效。Chaos Monkey 的名字来源于其工作的方式:如同一只野生的、武装了的猴子,在数据中心释放后,造成的严重破坏。
有了类似的故障注入的产品,工程师可以快速了解他们正在构建的服务是否健壮,有足够的弹性,可以容忍计划外的故障。
混沌工程实验像 Chaos Monkey 只是杀杀机器而已?这是错误的理解。回溯混沌工程发展的时间线,业界对混沌工程的理解是逐步深入的。Netflix 开发的 Chaos Monkey 成为了混沌工程的开端,但混沌工程不仅仅是 Chaos Monkey 这样一个随机终止 EC2 实例的实验工具。随后混沌工程师们发现,终止 EC2 实例只是其中一种实验场景。因此, Netflix 提出了 Simian Army 猴子军团工具集,除了 Chaos Monkey 外还包括:
Chaos Gorilla:Chaos Monkey 的升级版,模拟整个 Amazon Availability Zone 的故障,以此验证在不影响用户,且无需人工干预的情况下,能够自动进行可用区的重新平衡。
Chaos Kong:Chaos Gorilla 的升级版,模拟整个region(一个region由多个Amazon Availability Zone组成)的故障。
Latency Monkey:在 RESTful 服务的调用中引入人为的延时来模拟服务降级,测量上游服务是否会做出恰当响应。通过引入长时间延时,还可以模拟节点甚至整个服务不可用。
Conformity Monkey:查找不符合最佳实践的实例,并将其关闭。例如,如果某个实例不在自动伸缩组里,那么就该将其关闭,让服务所有者能重新让其正常启动。
Doctor Monkey:查找不健康实例的工具,除了运行在每个实例上的健康检查,还会监控外部健康信号,一旦发现不健康实例就会将其移出服务组。(隔离出服务,并且给相关人员足够的纠错时间,最终再关闭。)
Janitor Monkey:查找不再需要的资源,将其回收,这能在一定程度上降低云资源的浪费。
Security Monkey:这是Conformity Monkey的一个扩展,检查系统的安全漏洞,同时也会保证SSL和DRM证书仍然有效。
10-18 Monkey:进行本地化及国际化的配置检查,确保不同地区、使用不同语言和字符集的用户能正常使用Netflix。

图中正中央拿双枪的猴子就是Chaos Monkey,那么其它的猴子分别代表什么呢?
混沌工程
我们是否有过这样的经历:大半夜被电话叫醒,开始紧张地查验问题,处理故障以及恢复服务?也许就是因为睡前的一个很小的变更,因某种未预料到的场景,引起蝴蝶效应,导致大面积的系统混乱、故障和服务中断,对客户的业务造成影响。特别是近几年,尽管有充分的监控告警和故障处理流程,这样的新闻在 IT 行业仍时有耳闻。问题的症结便在于,对投入生产的复杂系统有多少信心。监控告警和故障处理都是事后的响应与被动的应对,那有没有可能提前发现这些复杂系统的缺陷呢?

混沌工程在分布式系统上进行由经验指导的受控实验,观察系统行为并发现系统缺陷,以建立对系统在规模增大时因意外条件引发混乱的能力和信心。
Principles of Chaos: Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
本文先从模拟 CPU 和 IO 打满的故障开始,随后引入了混沌工程的概念,不过这仅仅是个开始,在后面的文章中还会介绍如何模拟网络延时、网络丢包、网络故障、进程假死等故障,以此为媒介慢慢的为大家介绍一下混沌工程的东西。不,过有一点先要确立故障模拟只是混沌工程中的一个环节,并不是全部,而且混沌工程中的故障模拟不止包括节点级的故障,还包括集群级的故障、机房/数据中心级别的故障以及区域级别的故障等等。